
텍스트 마이닝
텍스트 마이닝 : 문자로 딘 데이터에서 가치 있는 정보를 얻어 내는 분석 기법
힙합가사 텍스트 마이닝
준비하기
- 패키지 준비
- KoNLP : 한글 자연어 분석 패키지
- KoNLP를 사용하기 위해서는 Java가 설치되어 있어야 한다
- KoNLP를 위한 패키지 설치
- KoNLP를 사용하기 위해서는 rJava, memoise가 설치되어 있어야 한다.
- 두 패키지를 설치 한 후 KoNLP를 설치
install.packages("rJava") install.packages("memoise") install.packages("KoNLP")
-
패키지 로드
library(KoNLP) library(dplyr) - 사전 설정
- KoNLP에서 지원하는 단어는 98만개 정도
- 형태소 분석을 위해 서전을 이용하도록 설정한다 ```r useNIADic()
#이 메시지가 나와야 한다 Backup was just finished! 983012 words dictionary was built. ```
- 데이터 불러오기
- readLines()로 데이터를 불러온다
txt <- readLines("hiphop.txt")
- readLines()로 데이터를 불러온다
- 특수문자 제거
- 문장에 특수문자가 포함되어 있으면 오류가 발생할 수 있기 때문에 stringr의 str_replace_all()을 이용해 특수문자를 빈칸으로 처리한다
install.packages("stringr") library(stringr) # 특수문자를 공백으로 처리 txt <- str_replace_all(txt, "\\W", " ")
가장 많이 사용된 단어 알아보기
-
명사 추출 : KoNLP - extractNoun()
extractNoun("대한민국의 영토는 한반도와 그 부속도서로 한다") [1] "대한민국" "영토" "한반도" "부속도서" "한" -
가사에서 명사 추출 후 빈도표를 만들기
# 가사에서 명사 추출 nouns <- extractNoun(txt) # 추출한 명사 list를 문자열 벡터로 변환 후 빈도표 생성 wordcount <- table(unlist(nouns)) # 데이터 프레임으로 변환 df_word <- as.data.frame(wordcount, stringsAsFactors = F) # 변수명 설정 df_word <- rename(df_word, word = Var1, freq = Freq) - 자주 사용된 단어 빈도표 만들기
- 두글자 이상 단어 추출
df_word <- filter(df_word, nchar(word) >=2 )
- 두글자 이상 단어 추출
-
상위 20개 단어 추출
top_20 <- df_word %>% arrange(desc(freq)) %>% head(20)
워드 클라우드 만들기
워드 클라우드 : 단어의 빈도를 구름 모양으로 표현한 그래프
- 패키지 준비
- wordcloud : 워드 클라우드 만들 수 있다
- RColorBrewer : 글자 색깔을 표현, R내장
install.packages("wordcloud") library(wordcloud) library(RColorBrewer) - 단어 색상 목록 만들기
- RColorBrewer - brewer.pal() : 색상 코드 목록을 만든다
pal <- brewer.pal(8,"Dark2") - Dark2 색상 목록에서 8개 색상 추출
- RColorBrewer - brewer.pal() : 색상 코드 목록을 만든다
- 난수 고정하기
- wordcloud는 실행할 때마다 다른 모양의 워드 클라우드를 만들어 낸다
- 항상 동일한 워드 클라우드가 생성되도록 난수 고정
set.seed(1234)
-
워드 클라우드 만들기
wordcloud(words = df_word$word, #단어 freq = df_word$freq, #빈도 min.freq = 2, #최소 단어 빈도 max.words = 200, #표현 단어 수 random.order = F, #고빈도 단어 중앙 배치 rot.per = .1, #회전 단어 비율 scale = c(4, 0.3), #단어 크기 범위 colors = pal) #색상 목록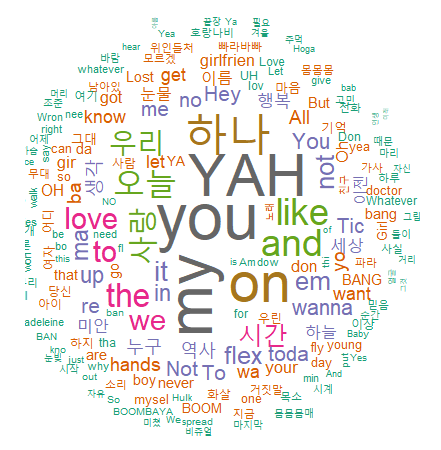
많이 사용된 단어일 수록 글자가 크고 가운데에 배치되며, 덜 사용된 단어일수록 글자가 작고 바깥쪽에 배치되는 형태로 구성되어 있다.
따라서 어떤 단어가 많이 사용됐는지 직관적으로 알 수 있다. - 단어 색상 바꾸기
- 단어 색상 목록을 이용하여 단어 색을 바꿀 수 있다.
pal <- brewer.pal(9,"Blues")[5:9]
- 단어 색상 목록을 이용하여 단어 색을 바꿀 수 있다.