한국복지패널데이터분석
한국복지패널데이터 분석준비
- 데이터 준비
- 한국복지패널 사이트 - SPSS파일 준비
- 패키지 설치 및 로드
- foreign - SPSS, SAS, STATA 등 다양한 통계분석 소프트웨어를 불러올 수 있다
install.packages("foreign") library(foreign) library(dplyr) library(ggplot2) library(readxl) - 데이터 불러오기
- foreign 패키지의 read.spss()
- 원본은 그대로 두고 복사본을 만들어 분석하는 것이 좋다
raw_welfare <- read.spss(file = "Koweps_hpc10_2015_beta1.sav", to.data.frame = T) welfare <- raw_welfare- to.data.frame : SPSS파일을 데이터 프레임 형태로 변환하는 기능, 설정하지 않으면 리스트 형태로 불러온다
- 데이터 검토
- head, View 등의 함수를 통해 구조와 특징을 파악해본다
- 변수명 바꾸기
- 보통 대규모 데이터는 변수의 수가 많고 코드로 되어있는 경우가 많기 때문에 쉬운 변수명으로 바꾼 후 사용하는 것이 좋다
- 대규모 조사자료는 보통 데이터의 특성을 설명해 놓은 코드북이 함께 제공되기 때문에 코드북을 보고 변수를 어떻게 지정하고 사용할 것인지에 생각을 해야한다.
데이터 분석 절차
1. 변수 검토 및 전처리
- 변수의 특성을 파악하고 이상치를 정제 후 파생변수를 만든다
- 변수 각각에 대해 실시
2. 변수 간 관계 분석
- 데이터를 요약한 표를 만든 후 결과를 쉽게 이해할 수 있는 그래프를 만든다
성별에 따른 월급차이
분석절차
- 변수 검토 및 전처리 : 성별, 월급
- 변수 간 관계 분석 : 성별 월급 평균표 만들기, 그래프 만들기
성별 변수 검토 및 전처리
- 변수 검토하기
- class() : sex변수의 타입 파악
- table() : 각 범주에 몇 명이 있는지
- 전처리 : 이상치 제외 및 결측치 처리
- 값의 의미를 이해하기 쉽도록 바꿈
- 이 예제에서는 sex가 1과 2로 되어있으므로, male과 female로 바꿔준다
welfare$sex <- ifelse(welfare$sex == 1, "male", "female")월급 변수 검토 및 전처리
- 이 예제에서는 sex가 1과 2로 되어있으므로, male과 female로 바꿔준다
- 변수 검토하기
- class() : income변수 타입 > numeric
- summary()
- qplot() : 최댓값까지 표현하도록 설정되어 있기 때문에 대다수인 0~1000까지가 잘 보이지 않음
- xlim(0, 1000)으로 0~1000까지만 표현되게 설정
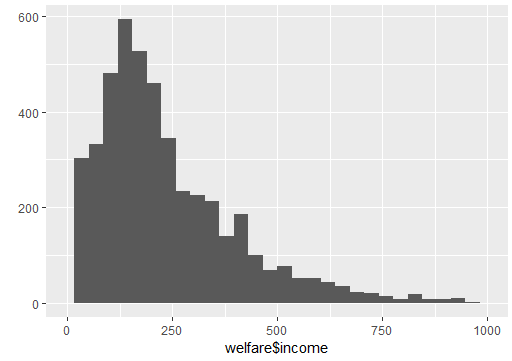
- 0~250만원 사이에 가장 많이 분포
- xlim(0, 1000)으로 0~1000까지만 표현되게 설정
- 전처리
- 코드북을 통해 1~9998 사이 값을 지니며 모름/무응답은 9999로 코딩되어 있음
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's 0.0 122.0 192.5 241.6 316.6 2400.0 12030 - 결측치 12030 : 월급을 받지 않는 응답자
- 또한, 최소값이 0이기 때문에 코드북에서의 1~9998 값이 아닌 이상치이므로 0을 결측처리
- 따라서, 0,9999일 때 결측 처리
welfare$income <- ifelse(welfare$income %in% c(0,9999),NA,welfare$income)성별에 따른 월급차이 분석
- 코드북을 통해 1~9998 사이 값을 지니며 모름/무응답은 9999로 코딩되어 있음
- 성별 월급 평균표
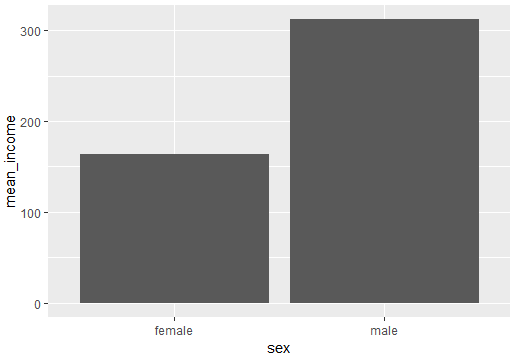
sex_income <- welfare %>% filter(!is.na(income)) %>% group_by(sex) %>% summarise(mean_income = mean(income)) sex_income # A tibble: 2 x 2 sex mean_income <chr> <dbl> 1 female 163. 2 male 312. - 그래프 만들기
ggplot(data = sex_income, aes(x = sex, y = mean_income)) + geom_col()