통계 분석 기법을 이용한 가설 검정
통계적 가설 검정이란?
기술 통계와 추론 통계
- 통계분석은 기술통계와 추론통계로 나뉜다.
- 기술통계 : 데이터를 요약해 설명하는 기법
- ex) 사람들이 받는 월급을 집계해 전체 월급 평균을 구하는 것
- 추론통계 : 숫자를 요약하는 것을 넘어 어떤 값이 발생할 확률을 계산하는 통계 기법
- ex) 수집된 데이터에서 성별에 따라 월급에 차이가 있을 때, 이러한 차이가 우연히 발생할 확률을 계산한다.
- 만약 차이가 우연히 나타날 확률이 작다면 성별에 따른 월급 차이가 통계적으로
유의하다고 한다. - 확률이 크다면 성별에 따른 월급 차이가 통계적으로
유의하지 않다고 한다.
- 기술통계 : 데이터를 요약해 설명하는 기법
- 일반적으로 통계 분석을 수행했다는 것은 추론 통계를 통해 가설 검정을 했다는 의미
- 기술 통계 분석에서 집단 간 차이가 있는 것으로 나타났더라도 우연에 의한 차이일 수 있기 때문에 신뢰할 수 있는 결론을 내리려면
유의확률을 계산해야 한다.
통계적 가설 검정
- 유의확률을 이용해 가설을 검정하는 방법
유의확률: 실제로는 집단 간 차이가 없는데 우연히 차이가 있는 데이터가 추출될 확률- 통계 분석 결과 유의확률이 크게 나타났다면
집단 간 차이가 통계적으로 유의하지 않다- 실제로 차이가 없더라도 우연에 의해 이 정도 차이가 발생할 확률이 크다는 것을 의미한다.
- 반대로 유의확률이 작게 나타났다면
집단 간 차이가 통계적으로 유의하다- 실제로 차이가 없는데 이 정도 차이가 관찰될 가능성이 작다, 우연으로 보기 힘들다.
t검정 - 두 집단의 평균 비교
t 검정은 두 집단의 평균에 통계적으로 유의한 차이가 있는지 알아볼 때 사용하는 통계 분석 기법.t.test()를 이용해 t검정을 할 수 있다.
compact 자동차와 sub 자동차의 도시 연비 t 검정
- ggplot2의 mpg데이터 이용
- 소형차와 suv가 도시 연비에서 통계적으로 유의한 차이가 있는지 알아보자
- mpg의 class,cty 변수만 추출한 뒤, class가 compact인 차와 suv인 차를 추출
mpg <- as.data.frame(ggplot2::mpg) library(dplyr) mpg_diff <- mpg %>% select(class, cty) %>% filter(class %in% c("compact", "suv")) t.test()를 이용한 t검정- ’~’를 이용해 비교할 값인 cty와 비교할 변수인 class 변수를 지정
- t 검정은 비교하는 집단의 분산이 같은지 여부에 따라 적용하는 공식이 다르다.
- 여기에서는 분산이 같다고 가정
t.test(data=mpg_diff, cty ~ class, var.equal = T) Two Sample t-test data: cty by class t = 11.917, df = 107, p-value < 2.2e-16 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: 5.525180 7.730139 sample estimates: mean in group compact mean in group suv 20.12766 13.50000- ` p-value < 2.2e-16 `
- 출력된 결과에서 p-value가 유의확률을 의미
- 일반적으로 유의확률 5% 기준에서 p-value가 0.05 미만이면
집단 간 차이가 통계적으로 유의하다고 해석한다. - p-value < 2.2e-16 : 유의확률이 2.2 앞에 0이 16개 있는 값보다 작다 ( 2.2 * 10 ^ -16)
- p-value가 0.05보다 작기 때문에 ‘compact와 suv간 평균 도시 연비 차이가 통계적으로 유의하다’고 해석할 수 있다.
sample estimates:- 각 집단의 cty평균
- compact의 도시 연비가 더 높다.
일반 휘발유와 고급 휘발유의 도시 연비 t 검정
mpg_diff2 <- mpg %>%
select(fl, cty) %>%
filter(fl %in% c("r", "p"))
t.test(data = mpg_diff2, cty ~ fl, var.equal = T)
Two Sample t-test
data: cty by fl
t = 1.0662, df = 218, p-value = 0.2875
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-0.5322946 1.7868733
sample estimates:
mean in group p mean in group r
17.36538 16.73810
- p-value가 0.05보다 큰 0.2875 : 일반 휘발유와 고급 휘발유를 사용하는 자동차 간 도시 연비 차이가 통계적으로 유의하지 않다.
- 고급 휘발유의 도시 연비 평균이 0.6 정도 높지만 이 정도 차이는 우연히 발생했을 가능성이 크다고 해석한다.
상관분석 - 두 변수의 관계성 분석
- 상관분석 : 두 연속 변수가 서로 관련이 있는지 검정하는 통계 분석 기법
- 상관분석을 통해 도출한
상관계수로 두 변수의 관련성의 정도를 파악할 수 있다. - 상관계수는 0~1 사이의 값, 1에 가까울 수록 관련성이 크다.
- 상관계수가 양수면 정 비례, 음수면 반 비례
실업자 수와 개인 소비 지출의 상관관계
- ggplot2의 economics를 이용
- unemploy와 pce(개인소비지출)간 통계적으로 유의한 상관관계가 있는지 알아보자
-
상관 분석은
cor.test()를 이용 (R 내장)ecconomics <- as.data.frame(ggplot2::economics) cor.test(economics$unemploy, economics$pce) Pearson's product-moment correlation data: economics$unemploy and economics$pce t = 18.605, df = 572, p-value < 2.2e-16 alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: 0.5603164 0.6625460 sample estimates: cor 0.6139997- p-value가 0.05 미만이므로, 실업자 수와 개인 소비 지출의 상관이 통계쩍으로 유의하다.
cor: 상관계수- 상관계수가 양수 0.61이므로, 실업자 수와 개인 소비 지출은 정비례관계이다.
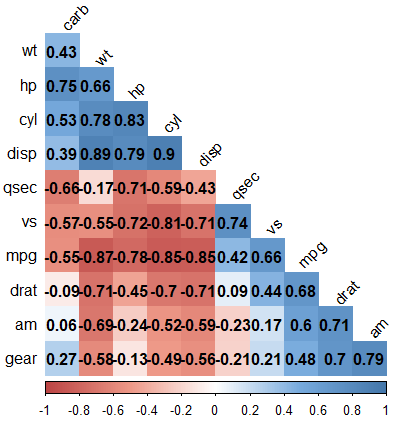
상관행렬 히트맵
- 여러 변수의 관련성을 한 번에 알아보고자 할 경우,
상관행렬을 만든다. - 상관행렬을 보면 어떤 변수끼리 관련이 크고 적은지 파악할 수 있다.
- mtcar 데이터 사용 (R 내장)
cor()으로 상관행렬을 만든다- 소수점 셋째 자리에서 반올림
car_cor <- cor(mtcars) round(car_cor, 2) mpg cyl disp hp drat wt qsec vs am gear carb mpg 1.00 -0.85 -0.85 -0.78 0.68 -0.87 0.42 0.66 0.60 0.48 -0.55 cyl -0.85 1.00 0.90 0.83 -0.70 0.78 -0.59 -0.81 -0.52 -0.49 0.53 disp -0.85 0.90 1.00 0.79 -0.71 0.89 -0.43 -0.71 -0.59 -0.56 0.39 hp -0.78 0.83 0.79 1.00 -0.45 0.66 -0.71 -0.72 -0.24 -0.13 0.75 drat 0.68 -0.70 -0.71 -0.45 1.00 -0.71 0.09 0.44 0.71 0.70 -0.09- cyl / mpg 교차 부분은 -0.85이므로, 연비가 높을수록 실린더 수가 적은 경향이 있다.
- cyl / wt 의 상관계수는 0.78이므로, 실린더 수가 많을 수록 자동차가 무거운 경향이 있다.
- 상관행렬을 히트맵으로 만들기
- 여러 변수로 상관행렬을 만들면 너무 많은 숫자로 구성되기 때문에 변수들의 관계를 파악하기 쉽지 않다.
- corrplot 패키지의
corrplot()을 이용해 상관행렬을히트맵으로 만들어 변수들의 관계를 쉽게 파악할 수 있다. -
히트맵 : 값의 크기를 색깔로 표현한 그래프
install.packages("corrplot") library(corrplot) corrplot(car_cor)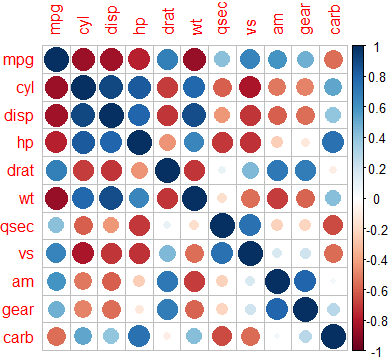
- 상관계수가 클수록 원의 크기가 크고 색깔이 진함
- 상관계수가 양수면 파란색, 음수면 빨간색
corrplot()의 파라미터로 그래프 형태를 바꿀 수 있다.corrplot(car_cor, method = "number")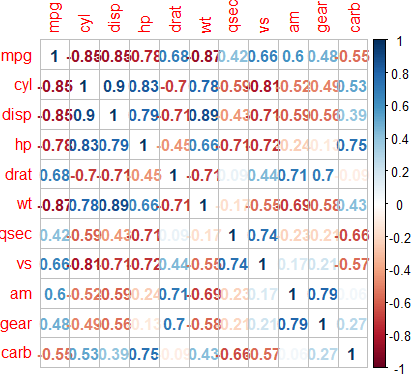
- 다양한 파라미터 지정
col <- colorRampPalette(c("#BB4444", "#EE9988", "#FFFFFF", "#77AADD", "#4477AA")) corrplot(car_cor, method = "color", # 색깔로 표현 col = col(200), # 색상 200개 선정 type = "lower", # 왼쪽 아래 행렬만 표시 order = "hclust", # 유사한 상관계수끼리 군집화 addCoef.col = "black", # 상관계수 색깔 tl.col = "black", # 변수명 색깔 tl.srt = 45, # 변수명 45도 기울임 diag = F) # 대각 행렬 제외